Software stack
The purpose of this page is to provide an overview of the layered architecture of ABB Ability™ History.
Overview
A key feature of ABB Ability™ History is to store data from devices and provide the data for the applications and users in an easy to use format.
You can think of this in terms of layers, where the data producers are at the bottom and the consumers are at the top. Between these, History binds these together, making the raw data produced by the devices to be easily usable by the consumers.

Layered architecture
In this section, we're going to introduce all the layers inside ABB Ability™ History. For each layer, we're going to explain the purpose of this layer and how it relates to other layers.
Producing data
The components in device connectivity layer receive data from the devices. These components write the data into the data storage layer. The data storage layer contains the data processing, aggregation, and storing to the database.
Using data
When clients want to use data, they use the external interfaces that service layer provides. These external interfaces have been built on top of the data abstraction interface, named VtrinLib. VtrinLib provides an ORM like abstraction on top of the data storage and exposes all the data within the same metainformation model.
The Vtrin driver layer implements the drivers for the data storage solutions. This layer translates VtrinLib calls to the API calls of the particular data storage in question.
-Simplified.png")
The layered architecture of ABB Ability™ History.
Device connectivity layer
Starting from the bottom of the stack, we have the Device connectivity layer. The purpose of this layer is to connect and implement data acquisition from the devices. The data collection is implemented with the active part (client ) in the device connectivity layer and the device is acting as the server.
When History starts, the RTDB-ServiceManager service starts active protocol services that communicate with the devices. Each service reads its configuration from the database. Based on this configuration, the connections to the Data Producers are established.
The active protocol services get data from the Data Producers either by polling or by using subscriptions and callbacks. The services read the configuration and insert data into the database by using internal APIs designed for high-throughput data production.
History supports the following protocols for data acquisition:
- Classic OPC (DA, HDA, and AE)
- OPC UA
- Modbus TCP
The corresponding services are:
- In Windows, RTDB-EcOpcClient to classic OPC servers and UA Servers.
- In Linux, RTDB-OpcUAClient to OPC UA Servers.
- RTDB-EcModbusMaster to Modbus slaves.
All services are configured using same configuration classes configuration classes.
Data storage layer
Next, we have the Data storage layer. The purpose of this layer is to provide the relational database services for storing and retrieving any data, and additionally special functionality for the time series data as described below.
Real-time value ingestion
History is optimized to support asynchronous high-throughput data writing. Data ingestion APIs insert the new data values into an in-memory ring buffer. Time series data processing service RTDB-CVMCServer takes the data values from the buffer, performs required preprocessing tasks including alarm limit checking according to the configuration for each signal, collects defined aggregates, and inserts the values into persistent history tables in the database. For more details about the data writing, see Feeding data.
Aggregated histories
History can automatically calculate and store aggregated time-series for a source time-series. These are called aggregated histories. RTDB-CVMCServer performs the online collection of the aggregates as part of the data ingestion process.
Cleaning up old data
History supports automatic data retention policy for old data. This prevents the data from piling up and taking up too much space. RTDB-Transformator service is responsible for removing old time-series data when it reaches the configured age limit.
Vtrin driver layer
Next, we have the Vtrin driver layer. The purpose of this layer is to enable Data Abstraction Interface (VtrinLib) to communicate with different database technologies. There exist ready made drivers for RTDB, OPC (DA, HDA, UA), and template for ODBC/SQL compatible relational databases that can be used with e.g. SQL Server. Additionally there is a SDK available to implement driver for any other data storage.
Data abstraction interface
The data abstraction layer provides a common interface, called VtrinLib, for accessing data. The purpose of this layer is to raise the level of information usability to a high enough level for applications.
Essentially, VtrinLib functions as an object-relational mapping (ORM), since it exposes an object model in its API to access the relational data in the data stores.
The Equipment model is one example of dynamic object models exposed by VtrinLib.
VtrinLib has a dedicated API for fetching time-series data (see Reading data).
Service layer
The service layer provides external APIs to ABB Ability™ History and services that are needed to implement applications and end customer solutions. External APIs contain OPC Server APIs (classic DA and HDA, and UA), OData, ODBC SQL, and VtrinLib .NET API. Details can be found in External interfaces. Other services contain e.g. Calculations and services to System architecture and topology.
Detailed view
This section contains a listing of History related technologies and which layer they belong to. The image below visualizes this. After the image, we provide links to other pages that explain these technologies in more detail.
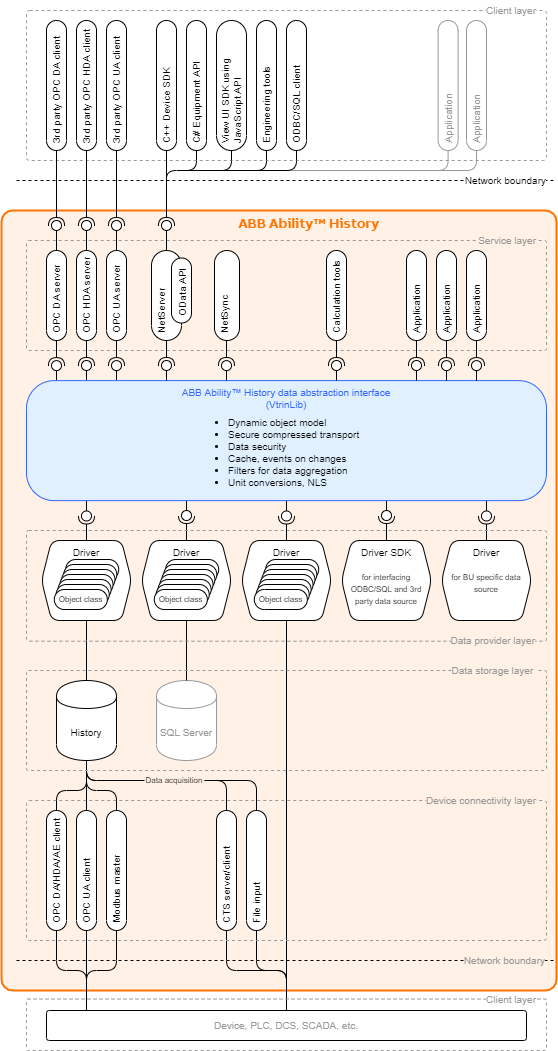
Client layer
- OPC Classic DA and HDA servers
- OPC UA Server
- Embedded C++ SDK onboarding
- Embedded C++ SDK
- C# Equipment API
- JavaScript API
- ODBC
- NetSync - Getting started
Service layer
Data abstraction interface
Data provider layer
Data storage layer
Device connectivity layer
Updated 9 months ago